
Huhtikuun lopulla HYTKI -hanke järjesti yhteistyössä PRIVASA -hankkeen kanssa webinaarin aiheesta Synteettinen data terveysalalla. Webinaarissa perehdyttiin aiheeseen lähtien yleiseltä tasolta case-esimerkkien kautta aina synteettisen datan ja yksityisyydensuojan välisen suhteen pohdintaan. Vastauksia saatiin mm. kysymyksiin mitä synteettinen data yleensäkään on ja mihin sitä voidaan käyttää, millaisilla käyttötapauksissa sitä on jo hyödynnetty ja miten yksityisyyden suojan näkökulmat vaikuttavat sen soveltumiseen käytännön TKI-toiminnassa.
Hyvinvointi- ja terveysdatan kansallinen innovaatioekosysteemi HYTKI-hankkeen yhtenä tehtävänä on kartoittaa siinä mukana olevien alueiden osaamisia ja kehittämiskärkiä ja tuoda niitä näkyväksi. Synteettinen data on yksi Turun alueen vahvuuksista, ja webinaarin puheenvuorot pitäneet asiantuntijat tulivatkin kaikki Turun alueen organisaatioista. Webinaarin yhteistyökumppanina toimi Turun yliopiston koordinoima PRIVASA-hanke, joka kehittää menetelmiä synteettisen datan tuottamiseen ja yksityisyyden säilyttävään data-analytiikkaan. Webinaarin moderaattorina toimi Janne Lahtiranta Turun yliopistolta ja Turku Science Parkista, ja HYTKI-hanketta esitteli Oulun yliopiston Maritta Perälä-Heape.
Mitä synteettinen data on?
Synteettisen datan äärelle webinaarissa johdatteli PRIVASA-hankkeen koordinaattori Tinja Pitkämäki. Hän kuvasi erilaisen datan asettumista jatkumolle aidosta datasta aggregoituun ja aina tekaistuun saakka. Hieno vertauskuva synteettiselle datalle löytyi light-colasta: näyttää ja maistuu aidolta. Synteettinen data ei siis ole mielikuvituksen tuotetta, vaan todellisten havaintojen pohjalta mallinnettua. Jotta synteettinen data olisi varteenotettava, tietosuojaa turvaava vaihtoehto aidolle terveysdatalle, tulisi sen olla anonyymia, oikeankaltaista ja hyödyllistä. Todistettavasti. Synteettisen datan tuottaminen on kuitenkin aina tasapainottelua käyttökelpoisuuden ja hyödyllisyyden sekä tietosuojan kesken.
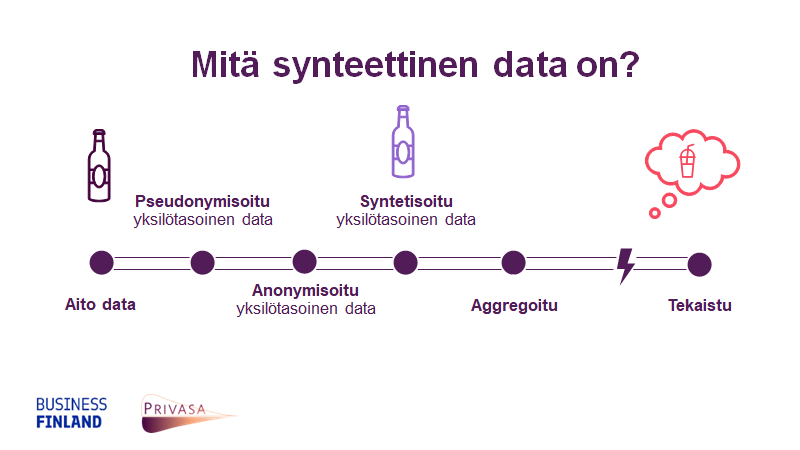
Data-jatkumo. Kuva Tinja Pitkämäki.
Mitä synteettisellä datalla voi tehdä?
Tietosuojanäkökulmien ja synteettisen datan käyttökohteiden pohdintaan siirryttiin tarkemmin seuraavassa, TYKS:n tietopalvelujohtaja Arho Virkin esityksessä. Lähtökohtana hänen esityksessään oli se, miten yliopistosairaaloissa dataa tarvitaan kaikkien sen tehtävien toteutukseen sekä niiden useat tietolähteet. Arhon esityksessä pureuduttiin tarkemmin myös siihen, miten eri tyyppiset datat suhteutuvat käyttörajoituksiin ja suojaamisvaatimuksiin. Arkaluontoinen, yksikkö- tai yksilötason data on suojattava, ja siihen kohdistuu käyttörajoituksia. Näin sitä ei voida niin sujuvasti käyttää esim. tutkimuksessa, vaan esimerkiksi synteettisen datan käyttäminen voi olla tarpeen.
Synteettisen datan potentiaalisina käyttökohteina esiin nostettiin lisäksi esille mm. opetusmateriaalit, ohjelmistotestaaminen, tilastollisen mallinnuksen ensivaiheet, kaupallisen innovaatiotoiminnan tukena sekä esimerkiksi erilaiset hackathonit.
Synteettisen datan käyttökohteet herättivät keskustelua. Esimerkiksi siitä keskusteltiin, onko synteettisen datan tuottamiseen olemassa jo valmiita prosesseja tai ratkaisuja. Tämä nähtiin vielä avoimena tutkimuskysymyksenä, vaikka markkinoilla onkin jo joitakin ratkaisuja, jotka väittävät tuottavansa synteettistä dataa. Nämä eivät asiantuntijoiden mukaan kuitenkaan ole vielä täysin luetettavia tuottamansa datan hyödyllisyyden tai anonyymiyden suhteen, jos synteettistä dataa tuotetaan hyvin kapeasta tai esim. vanhentuneesta datasta. Positiivisena loppukaneettina Arhon esityksessä nostettiin esiin se, että Suomessa on kaikki edellytykset tuottaa ajankohtaista synteettistä dataa.
Case-esimerkkejä lääketieteelliseen kuvantamiseen liittyen
Seuraavaksi webinaarissa tarkasteltiin synteettisen datan ja hajautetun oppimisen (federated learning) hyödyntämistä lääketieteellisen kuvantamisen käyttötapauksissa. Eri tutkimusprojektien käyttötapauksia esitteli tutkija Mojtaba Jafaritadi (Turun ammattikorkeakoulu sekä Stanfordin yliopisto). Käyttötapaukset koskivat mm. synteettisiä aivojen magneettikuvia, Sydämen positroniemissiotomografiaa sekä synteettistä röntgenkuvausten dataa kuvien tunnistamisessa. Esityksessä käyttötapauksiin tutustuttiin hyvinkin teknisellä tasolla, ja aiheista kiinnostuneet saavat varmasti lisätietoja käyttötapausesimerkeistä PRIVASA-tiimiltä!
Synteettinen data ja yksityisyys
Webinaarin päättävässä esityksessä PRIVASA-hankkeen tutkija Valtteri Nieminen tarkasteli tarkemmin synteettisen datan ja yksityisyyden kysymyksiä. Esityksessään hän mm. pohti sitä, mitä onnistunut synteettisen datan anonymisointi voi tarkoittaa. Oleellista on, että se riippuu aina käyttötarkoituksesta. Joskus datan syntetisointi ei kannata ja voi olla jopa epäeettistä, jos sen hyödyllisyys kärsii vähänkin vaarantaen esimerkiksi potilasturvallisuutta hoitovirheiden riskin kasvamisen myötä.
Vastakohtana tällaiselle tilanteelle esiin nostettiin esimerkiksi yritysten lähettämän markkinointikirjeet, jossa hieman pieleen menneet tuotesuositukset eivät aiheuta vaaraa tai riskiä kenellekään, vaan tärkeämpää on yksityisyydensuoja ja käytetyn datan anonyymius.
Anonyymiuden suhteen relevantti riski myös terveysalalla muodostuu, kun useita datalähteitä yhdistellään. Tällöin yksittäisenä datasettinä anonyymiksi luullun datan pohjalta yksilön tunnistaminen saattaakin tulla mahdolliseksi. Datan hyödyntäjien ja omistajien onkin oltava tarkkana, kun eri datalähteitä yhdistellään. Erilaiset riskiarviot ovatkin varmasti kaikille datan hyödyntäjille jo tuttuja.
HYTKI-webinaarit jatkuvat syksyllä
Huhtikuun webinaari oli ensimmäinen HYTKI:n webinaarisarjasta, jossa esitellään mukana olevien alueiden kehittämiskärkiä. Webinaarisarja jatkuu syksyllä, pysythän siis kuulolla! Luvassa ainakin asiaan kyberturvallisuudesta terveysalalla sekä hyvinvointi- ja liikuntadatan hyödyntämisestä.